
Introduction
As the use of Generative AI and LLMs continues to grow, so do the threats targeting them. Traditional cybersecurity frameworks like MITRE ATT&CK are excellent for modeling IT infrastructure attacks, but they fall short when applied to AI systems. That’s where MITRE ATLAS comes in — a purpose-built framework for mapping threats against AI technologies.
In this post, we’ll explore what MITRE ATLAS is, why it was created, and how it helps us think critically about AI-specific attack surfaces. To demonstrate this, we’ll walk through a real-world-inspired case study: the OpenAI vs. DeepSeek incident, where OpenAI accused DeepSeek of stealing its model intelligence via a technique known as model distillation.
Why MITRE ATLAS Was Created?
MITRE ATT&CK has long been the gold standard for classifying tactics and techniques used in traditional IT-based cyberattacks. However, LLMs and AI systems introduce entirely new risks — like prompt injection, model extraction, training data poisoning, and adversarial inputs — that simply don’t fit into the ATT&CK model.
The attack surface of AI is fundamentally different:
- LLMs are interactive, probabilistic systems.
- They rely on massive training datasets, often including sensitive or proprietary information.
- Their behavior can be manipulated not by exploiting code, but by manipulating inputs or stealing outputs.
To address these AI-native risks, MITRE created ATLAS — the Adversarial Threat Landscape for Artificial-Intelligence Systems.
What the MITRE ATLAS Framework Contains?
MITRE ATLAS organizes threats into a matrix of tactics and techniques — similar in concept to ATT&CK, but tailored for AI systems. The framework captures:
- Adversarial AI techniques (e.g., model inversion, training data poisoning)
- Attack phases (e.g., reconnaissance, model manipulation, evasion)
- Real-world case studies and attack scenarios
You can explore the full ATLAS matrix using the official MITRE Navigator here
MITRE ATLAS Navigator Tool Overview
The ATLAS Navigator is a browser-based tool that lets you view and customize the ATLAS matrix. You can use it to:
- Highlight specific tactics or techniques relevant to your scenario
- Create your own threat models for AI/ML systems
- Save and export customized attack maps
It’s particularly useful for red and blue teams building threat models for LLMs, computer vision models, or even autonomous agents.
The OpenAI vs. DeepSeek Case
In early 2024, OpenAI accused DeepSeek of replicating its model’s behavior through a technique called model distillation. The claim was that DeepSeek used OpenAI’s own publicly accessible model (e.g., GPT-4) to train a rival model by feeding it carefully crafted inputs and collecting outputs to mimic its behavior.
While the case remains a public allegation and not a legal finding, it presents a valuable learning opportunity to understand how such attacks could occur — and how they map to MITRE ATLAS.
Mapping the Incident to MITRE ATLAS
If we assume that the model distillation attack against OpenAI by DeepSeek occurred as claimed, we can map the attack steps to MITRE ATLAS tactics and techniques. The mapping, as shown in the matrix, includes both the highlighted and non-highlighted techniques.
You can dowload the populated MITRE ATLAS for this incident here
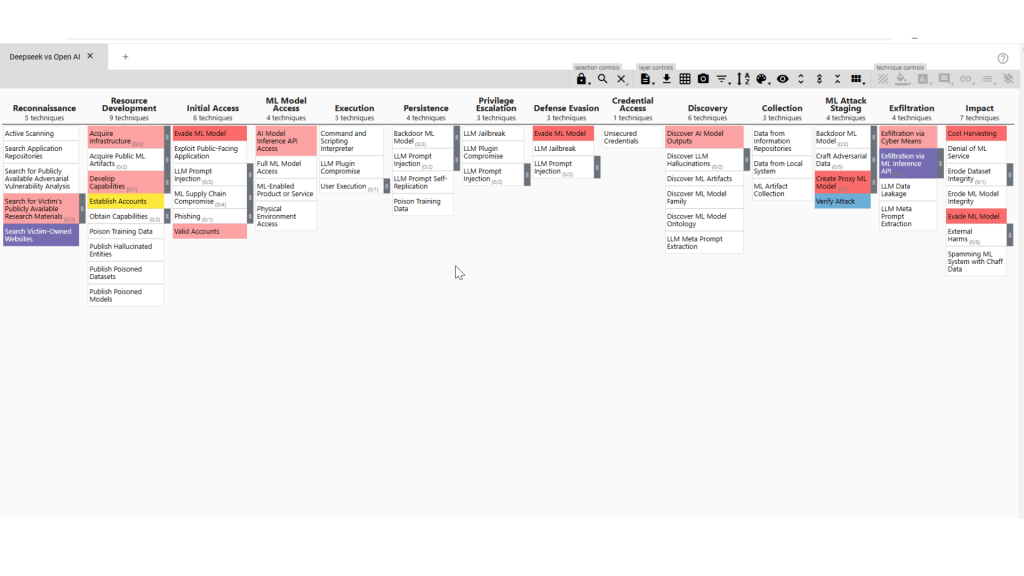
Highlighted Techniques:
1. Reconnaissance:
- Search for Publicly Available Adversarial Vulnerability Analysis: If any vulnerability assessments or model evaluations were published by OpenAI, DeepSeek could use them to refine its distillation techniques.
- Search for Victim-Owned Websites: OpenAI’s own documentation or API endpoints may have been examined to gather data on model specifications or query structures.
2. Resource Development:
- Establish Accounts: DeepSeek would have needed accounts on cloud platforms or API access to run its model distillation operations.
- Develop Capabilities: The distillation technique itself is a capability that must be developed — possibly involving custom scripts or machine learning pipelines.
- Acquire Infrastructure: Adversaries may buy, lease, or rent infrastructure for use throughout their operation. A wide variety of infrastructure exists for hosting and orchestrating adversary operations.
3. Initial Access:
- Evade ML Model: Since the model distillation is based on querying the model rather than exploiting a technical vulnerability, the focus here is on avoiding detection by evading model monitoring or security checks.
- ML Prompt Injection: DeepSeek could have crafted specific prompts to extract certain responses, aiding in the distillation process.
4. ML Model Access:
- AI Model Inference API Access: The distillation attack is fundamentally based on repeatedly querying the model to infer its logic.
- Full ML Model Access: If OpenAI’s model was accessible without strict rate limiting or API protections, DeepSeek would have had significant leverage in extracting valuable responses.
5. Defense Evasion:
- Evade ML Model: The querying process would likely be designed to avoid triggering rate limits or security alerts, ensuring the attack remains undetected.
6. Discover AI Model Ontology:
- Adversaries may discover the ontology of an AI model’s output space, for example, the types of objects a model can detect. The adversary may discovery the ontology by repeated queries to the model, forcing it to enumerate its output space.
7. ML Attack Staging:
- Verify Attack: Once the cloned model is complete, DeepSeek would need to verify its functionality, comparing outputs to those generated by the original OpenAI model.
8. Exfiltration:
- Exfiltration via ML Inference API: The primary data extraction occurs through the inference API — querying the model and collecting responses.
9. Impact:
- Cost Harvesting: By replicating OpenAI’s model, DeepSeek could effectively avoid the costs associated with training a high-quality model.
- Evade ML Model: The cloned model may be designed to bypass OpenAI’s detection mechanisms, especially if OpenAI employs watermarking or other integrity checks.
You can visualize this mapping using a custom ATLAS layer in the Navigator tool, highlighting the specific tactics and techniques involved.
Why This Mapping Matters?
Creating a threat model using MITRE ATLAS helps:
- Understand how attackers might target AI systems in practice
- Prepare security teams to monitor, detect, and prevent such tactics
- Bridge the gap between theory and real-world AI security operations
For organizations building or deploying AI systems, using ATLAS can help formalize your risk assessments and incident response planning — just as ATT&CK does for traditional IT.
Final Conclusion — Wrapping Up the GenAI Cybersecurity Series
This post marks the final part of our GenAI Cybersecurity series. Across these five in-depth posts, we explored the unique security landscape surrounding Large Language Models — from their architecture and attack surfaces to real-world vulnerabilities and AI-specific threat modeling using MITRE ATLAS.
Whether it was understanding prompt injection, analyzing insecure OLAMA server exposures, securing APIs with NGINX, or mapping adversarial techniques in AI with the ATLAS framework, this series was designed to give you a practical and strategic foundation in LLM cybersecurity.
Generative AI is evolving fast, and so are the threats targeting it. By staying informed, thinking like an attacker, and applying the right defensive controls, you can stay ahead of the curve.
Thank you for following along. If you found this series valuable, feel free to share it and check out the full GenAI Cybersecurity course on Udemy for hands-on labs, demos, and deeper technical insights.


Leave a comment