Why Understanding Large Language Models Matters for Cybersecurity: Deep Knowledge Fuels Robust Defense
To effectively secure advanced AI systems, a deep understanding of their inner workings is essential. By dissecting the architecture, learning mechanisms, and processing flow of LLMs, cybersecurity professionals can better anticipate vulnerabilities and design targeted defense strategies. After all, you can only protect what you truly understand.
Understanding Large Language Models: From Neural Networks to Transformer Brilliance
In this article — the first of our blog series on LLM cybersecurity — we’ll build a strong foundation to understand how LLMs work, how they fit into the broader world of GenAI, and why their security is a serious emerging concern.
Let’s get started then

What is a Large Language Model (LLM)?
An LLM is a deep learning model trained on massive text datasets to generate human-like responses. Think of it as:
A very advanced auto-complete system that can read your input and generate paragraphs, code, emails, or even poetry in return.
These models work by predicting the next word in a sequence based on patterns learned during training. What makes them powerful is the sheer scale:
• Billions of parameters (like neurons)
• Trained on internet-scale datasets
• Can process, summarize, and generate complex content
How are LLMs Different From Generative AI?
While LLMs are the text-focused branch of Generative AI with models such as GPT, Gemini, BERT etc., the broader GenAI ecosystem includes models that can generate:
• Images (e.g., Midjourney, DALL·E)
• Videos (e.g., RunwayML)
• Music (e.g., Jukebox)
• Code (e.g., Copilot, Mutable AI)
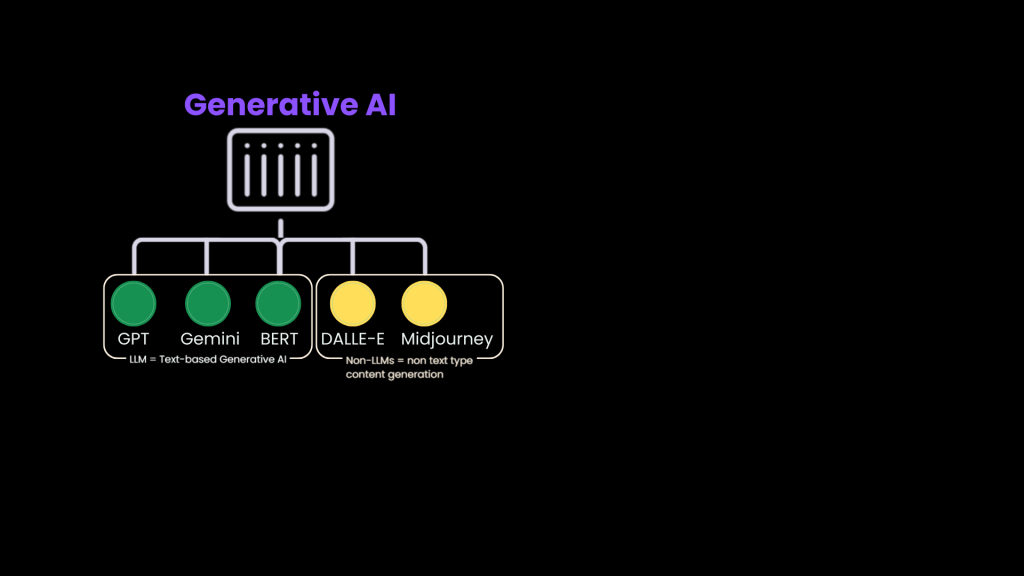
So:
GenAI is a broad category and LLMs are a subset of Generative AI — specifically trained for language understanding and generation.
This distinction is important because the risks and safeguards differ. What’s a hallucination in a text model may be misinformation; in an image model, it may be visual deepfake. The security implications vary accordingly.
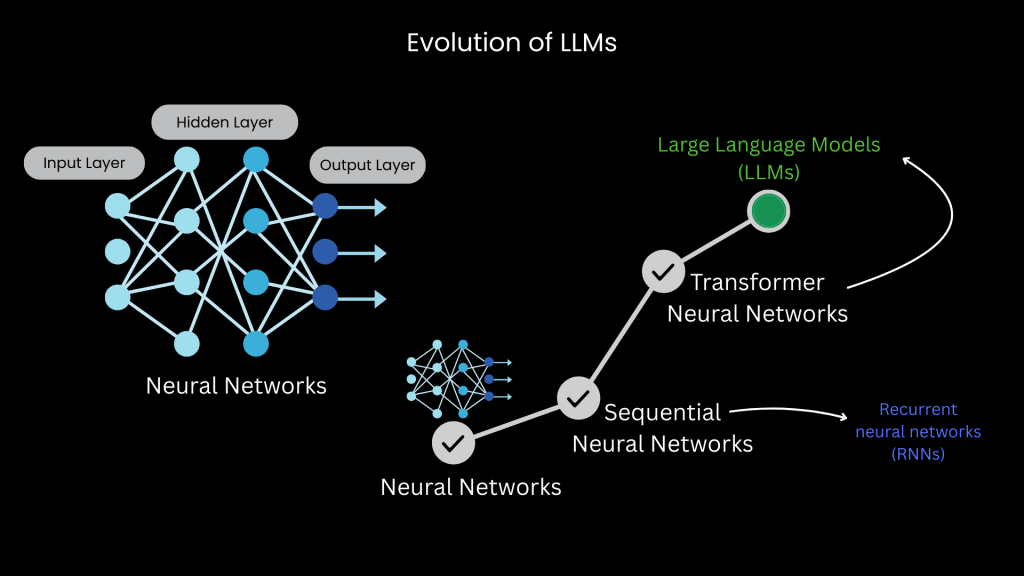
The Evolution of Language Models: From RNNs to Transformers
To understand how today’s Large Language Models (LLMs) became so powerful, we must first trace the history of neural networks in language processing.
1. Early Neural Networks: Sequential Language Understanding
Neural networks started off with simple architectures focused on learning patterns through input-hidden-output layers.
2. Recurrent Neural Networks (RNNs)
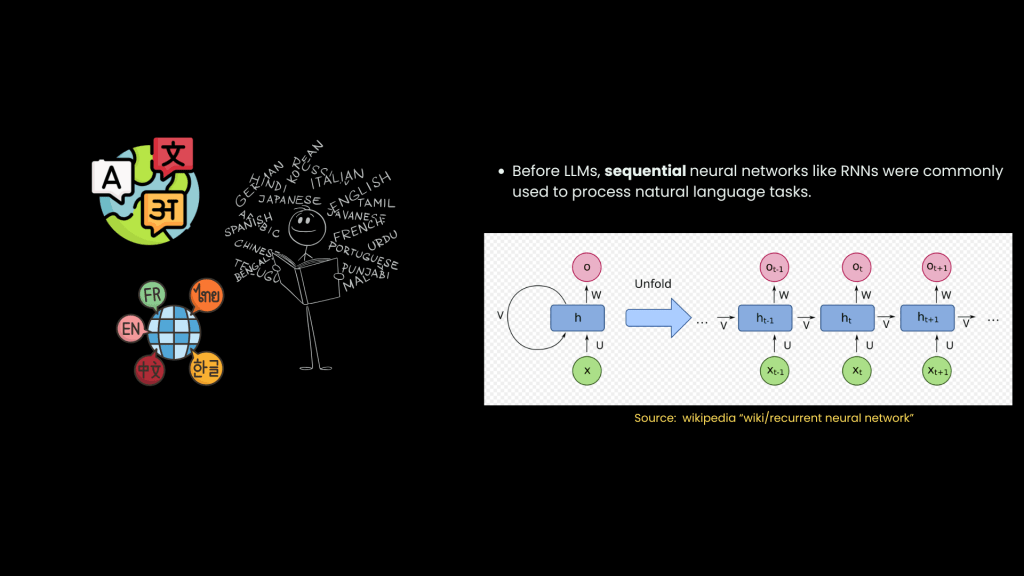
RNNs were among the earliest neural networks used for processing natural language tasks like text classification, sentiment analysis, and machine translation. They were categorized as sequential neural network models.
The word ‘sequential‘ is important here, because they processed one word input at a time, because in order to understand human language, word order matters, and this sequential processing allowed them to capture the word order in language.
For example, the sentence “The cat chased the mouse” conveys a very different meaning than “The mouse chased the cat,” and RNNs could capture that difference.

While that was a strength, it also became a weakness:
- RNNs struggled with long sequences, often forgot earlier parts of a paragraph or sentence.
- Poor long-term memory made it hard to understand context in essays or documents.
- Slow training — couldn’t easily leverage GPUs for speed.
- Limited scalability — hard to train on massive datasets.
3. From RNNs to Transformers
In 2017, Google introduced the Transformer architecture — a paradigm shift. Instead of sequential processing, Transformers introduced self-attention, which lets the model learn context across the entire sentence simultaneously.
This allowed for:
• Better understanding of relationships between distant words
• Parallel training across tokens — speeding up model training on massive datasets
Transformers became the foundation of modern LLMs like GPT, BERT, and Claude.
Why Transformers Replaced RNNs
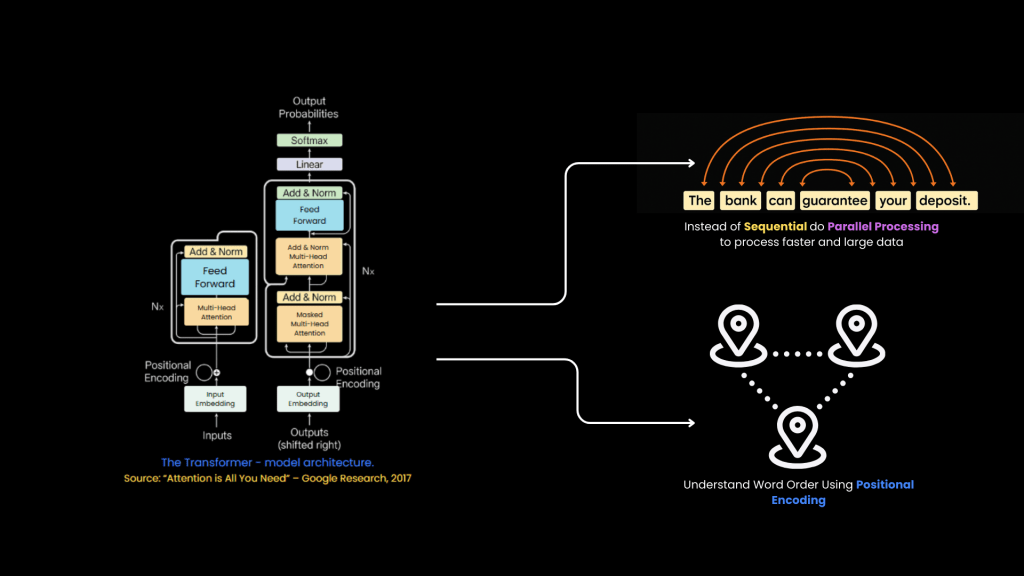
The following image shows the Transformer model architecture (taken from the Google Research paper ‘Attention Is All You Need’).
They were:
- Originally designed for translation tasks.
- Allowed parallel processing — unlike RNNs that process word by word.
- Highly scalable — can be trained on massive datasets efficiently.
- Powered large models like GPT-3, trained on ~45 TB of text (nearly the entire public web).
Key Innovations in Transformers
Transformers revolutionized the field of natural language processing by introducing three key innovations: Attention, Self-Attention, and Positional Encodings.

a) Postional Encoding
Since Transformers don’t process words in sequence, they need to know word positions. Positional encoding solves this by tagging each word with its position in the sentence.

b) Attention
Before diving into self-attention, it’s important to understand the foundation: Attention.
The idea of attention itself is not new. It was first introduced in 2014 by researchers Bahdanau, Cho, and Bengio in their influential paper titled:
“Neural Machine Translation by Jointly Learning to Align and Translate.”
In this paper, the authors proposed a mechanism that allowed neural networks to focus on specific parts of the input sequence while generating the output. This mechanism, called attention, enabled the model to look back at the input sentence and decide which words were most relevant for generating each word in the output.
What Did Attention Achieve?
- Instead of rigidly processing words in a sequential order, attention allowed the model to cross-reference input words with output words.
- It could dynamically adjust focus, giving higher weights to more relevant words.
- For example, in translation tasks, it helped align phrases across languages with differing word orders.
This is particularly important when translating between languages because each language has its own grammatical structures and word orders. Let’s understand this with an example.
Example: English to Hindi Translation
Input Sentence (English):
“The agreement on the European Economic Area was signed in August 1992.”
If we attempt a direct word-for-word translation without attention, the result would be a jumbled, nonsensical sentence in Hindi. This is because Hindi follows a Subject-Object-Verb (SOV) order, unlike English, which follows a Subject-Verb-Object (SVO) order.

How Attention Mechanism Fixes This:
Instead of rigidly translating word-for-word, the attention mechanism enables the model to look at every word in the input sentence and decide which words are most relevant when generating each output word.
- When the model processes the word “agreement”, it identifies that in Hindi, the verb “was signed” (किए गए थे) must come at the end of the sentence.
- When processing “European Economic”, it understands that these adjectives should come before the noun “agreement”, not after.
- For “August 1992”, the model recognizes that these time expressions should follow the verb.
How It Works:
1. Input Processing:
- The model looks at each word in the input sentence and calculates how much focus or attention should be given to each word in the sentence.
2. Cross-Attention:
- In the earlier neural networks, attention was applied cross-input, meaning the model repeatedly looked back at the input sentence while generating each word in the output.
- For example, when generating the Hindi word “समझौते” (agreement), the model looks at “agreement”, but also considers surrounding words like “on,” “European,” and “Economic” to determine the correct position and grammatical structure.
3. Generating the Output:
- The model then generates each output word by attending to specific input words based on their relevance.
- This process continues until the entire sentence is translated, resulting in a grammatically correct Hindi sentence: “यूरोपीय आर्थिक क्षेत्र पर समझौते पर अगस्त 1992 में हस्ताक्षर किए गए थे।”
So that was the “Attention” concept. Now, let’s understand “Self-Attention”, which was built on Attention.
c) From Attention to Self-Attention

2017 — The Landmark Shift to Self-Attention
Three years later, in 2017, researchers at Google released the groundbreaking paper titled: “Attention Is All You Need.”
- While traditional attention mechanisms looked back at the input sequence to align with the output, self-attention turned the focus inward.
- The model now evaluated how each word related to every other word within the same input sequence, not just between input and output.
This shift was monumental. By enabling the model to process all words simultaneously and assess their interrelations, the transformer architecture achieved parallel processing, making it far more efficient and scalable than earlier RNN-based models.
Why Is It Called “Attention Is All You Need”?
The title itself was a bold statement — the authors claimed that attention, particularly self-attention, was powerful enough to replace traditional sequential processing steps like RNNs and LSTMs. And they were right. The transformer model, built entirely on self-attention, became the foundation for state-of-the-art LLMs like GPT, BERT, and Claude.
Instead of connecting the input to a separate output stream, self-attention operates entirely within the input itself. Each word (or token) looks at every other word in the same sentence to understand context. This mechanism enables the model to capture deeper relationships, such as which words modify or depend on each other.
So, in self-attention, there’s no cross-attention. The model first fully processes the input using self-attention, and then generates the output based on that internalized understanding.
Let’s understand this with an example:

Example: Disambiguating the Word “Bank” Using Self-Attention
To understand how self-attention works, consider the following two sentences:
- “The bank can guarantee your deposit.”
- “The River Ganga has a beautiful bank.”
Both sentences contain the word “bank,” but the meaning is entirely different in each context. In the first sentence, “bank” refers to a financial institution, while in the second, it refers to the shore of a river.
How Self-Attention Resolves This Ambiguity:
In self-attention, the model examines every word in the sentence and assesses how each word relates to every other word in that sentence. This approach allows the model to dynamically adjust the meaning of words based on their surrounding context.
Step 1: Input Processing
- The model processes the input sentence and generates a context vector for each word.
- For the word “bank,” the model generates a vector based on its position, neighboring words, and overall context.
Step 2: Attention Score Calculation
- The model calculates attention scores for each word relative to “bank.”
- In the first sentence, words like “deposit,” “guarantee,” and “can” receive higher attention scores, indicating that “bank” is associated with financial terminology.
- In the second sentence, words like “river” and “beautiful” receive higher attention scores, indicating that “bank” refers to a riverbank.
Step 3: Contextual Understanding
- Based on these scores, the model generates a context vector for “bank” that captures its intended meaning:
- In the first sentence, the context vector aligns with financial terms like “money,” “deposit,” and “loan.”
- In the second sentence, the context vector aligns with natural or geographical terms like “shore,” “river,” and “sand.”
How Self-Attention Differs from Traditional Attention?
Traditional attention mechanisms operate by focusing solely on the input sequence when generating the output. The model scans the entire input sentence, assigns attention scores to each word, and then generates each output word based on the most relevant input words.
In contrast, self-attention goes beyond input-output alignment. It examines all words within the same sentence, including both input and output words, simultaneously. This means that while generating the word “bank,” the model considers how “bank” relates to every other word in the same sentence, not just its corresponding input word.
- Traditional Attention: Focuses on input words based on the output word being generated.
- Self-Attention: Focuses on all words within the same sentence, allowing the model to resolve ambiguities and understand contextual relationships more effectively.
This inward focus is crucial for disambiguating words with multiple meanings and enables the model to build a richer understanding of the sentence structure.
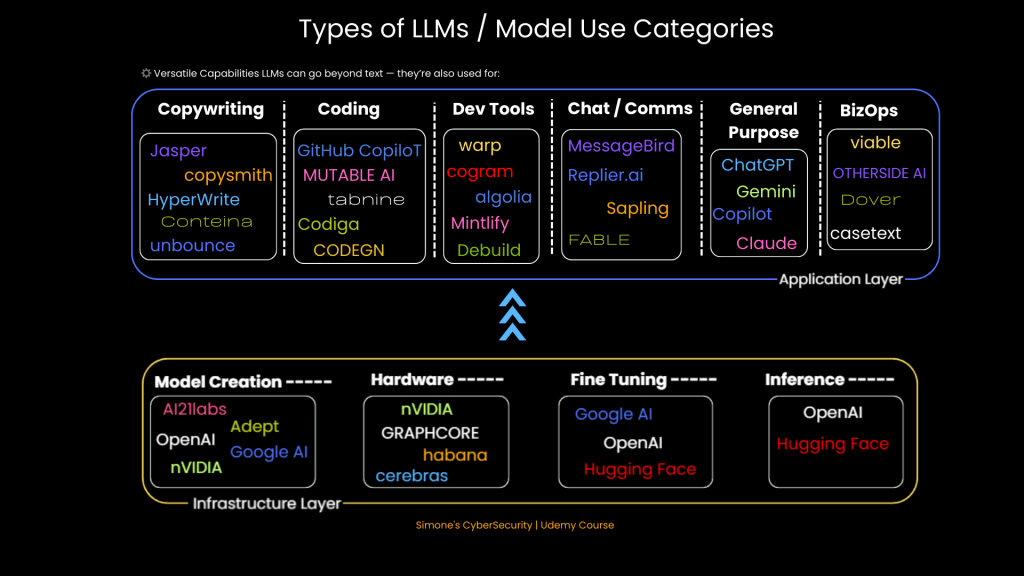
Transformers in Action: From GPT to Claude
Today’s LLMs like GPT-4, Claude, and Mistral use stacked transformer blocks to generate human-like text. They’re trained on petabytes of data and power everything from customer support to AI coding assistants.
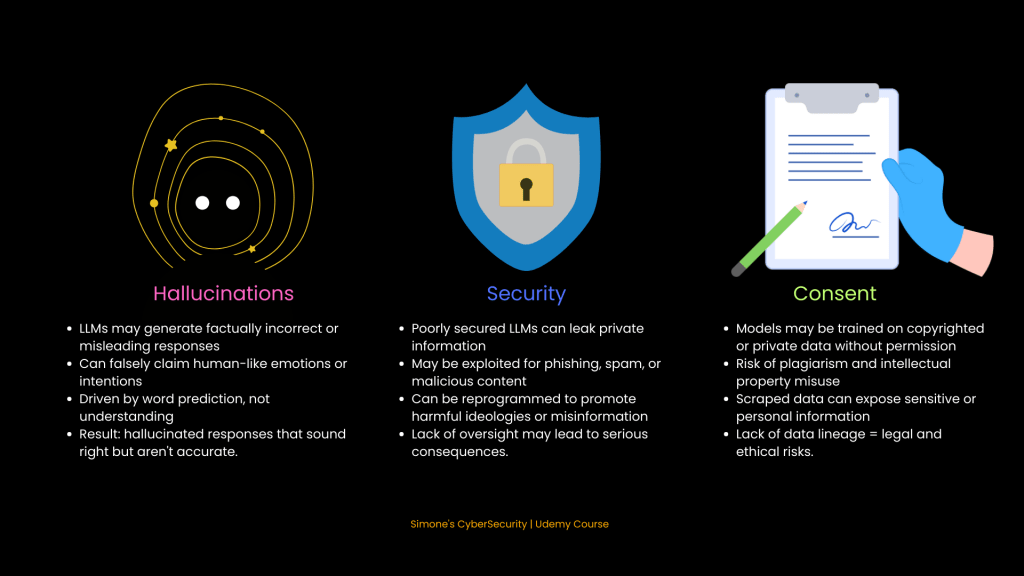
Challenges of LLMs
Despite their power, LLMs are not perfect. They hallucinate, leak data, and can be misused without proper safeguards.
That’s all for Part 1 of our GenAI Cybersecurity series. We’ve laid the groundwork by exploring what Large Language Models are and how they evolved.
Now, in the next part, we will break down the internal architecture of an LLM system, layer by layer, from the Application Layer to the Infrastructure Layer. This deeper understanding will help us identify potential attack surfaces and vulnerabilities.


Leave a comment